Algorithms¶
Word indexing¶
Each shared file and directory is indexed by its name which is split in words. A search will be based on this index.
See the associated prototype here for some performance measures : Word index prototype.
Word splitting (Tokenizer)¶
Theses steps are valid independently of the language.
- Some character are replaced by a another, for example : ['é', 'ë',..] => 'e'. The goal is to remove all accent.
- All characters are converted to lower case.
- Each file is split in word, there is a set of characters which will use as delimiter between the word like [' ', '#', '.', '?',..].
This process is also valid for the user input when searching.
Structure¶
A simple tree structure is used like this :
struct Node {
QChar letter;
QList<Node*> children;
QList<T> itemList;
};
Searching into the tree¶
The match of a word can be partial from the beginning, for example train will match training.
- Match each character of the searched word against the letter of the children of the root node recursively
- If the match failed the result is empty
- Else, the result contains all items from the sub tree
In the worst case the number of iteration is N*36 for a latin alphabet (a-z, 0-9). Where N is the number of character of the searched word.
Searching among other peers¶
For a functional description see here : Functional definition
- The words are sent to each peers (see the message Find here : Protocol core-core)
- Each peer will do a search for each word into its index
- The results for each search will be merged according the schema below
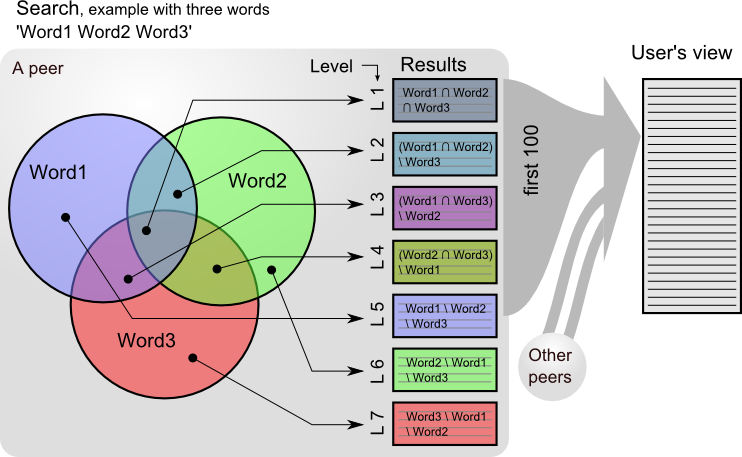
This schema depicts how the results are sorted from one peer. Each peer result are then merged.
Peer ID¶
Each peer owns a peer id which is unique and generated during the first start. This ID is used to identify a peer, it's better than the previous usage of peer IP, considering this situation :
- A put in queue a file entry f from B, B doesn't know the hashes of this file entry.
- B change his IP address.
- A want to download f, it can ask B for the hashes even B's IP changed.
Core threads¶
There are three kind of threads in the core in addition to the main thread :- Downloading thread :
DownloadManager::ChunkDownloader - Uploading thread :
UploadManager::Uploader - Updating file cache thread :
FileManager::FileUpdater
These threads exist only for treating IO in a parallel manner. The goal is not the computation nor robustness.
Updating the file cache¶
Here is the algorithm for the thread (FileManager::FileUpdater) which will periodically update the file cache and persist it.
There is a prototype for the watcher here : Watcher prototype
D : The set of shared directories
T : Time during which the hashes are computed (for example 30s)
F : A set containing file with unknown hashes, initially empty
W : the directory watcher
// First synchronize (at start)
For each d in D (recursively) :
- Add d to W
- Synchronize physical folders and files with d content
- Add in F the files which don't have hashes
Loop :
t : Time.now
For each f in F :
- Compute the unknown hash of files f
- Remove f from F
If (Time.now - t) > T : break
- Wait for changes for a period of (if F is empty then INFINITE else 0)
- When a modification occurs synchronize the file/folder
- Add each new file in F
- Persist the entire cache in a file (only every ~30min)
Downloading¶
See here : Protocol_core-core
Updated by Greg Burri over 13 years ago · 35 revisions