Actions
Algorithms » History » Revision 18
« Previous |
Revision 18/35
(diff)
| Next »
Greg Burri, 08/07/2009 01:37 PM
Algorithms¶
Searching¶
For a functional description see here : Functional definition
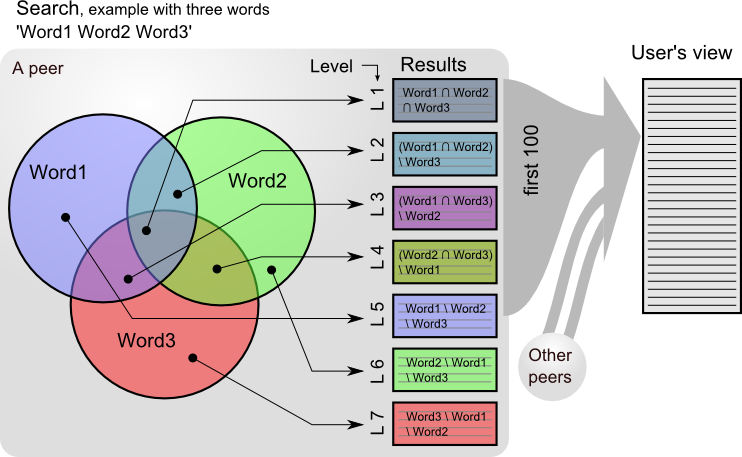
This schema depicts how the results are sorted from one peer. Each peer result are then merged.
Peer ID¶
Each peer owns a peer id which is unique and generated during the first start. This ID is used to identify a peer, it's better than the previous usage of peer IP, considering this situation :
- A put in queue a file entry f from B, B doesn't know the hashes of this file entry.
- B change his IP address.
- A want to download f, it can ask B for the hashes even B's IP changed.
Core threads¶
There are three kind of threads in the core in addition to the main thread :- Downloading thread :
DownloadManager::ChunkDownloader - Uploading thread :
UploadManager::Uploader - Updating file cache thread :
FileManager::FileUpdater
Updating the file cache (Obsolete, must be rewritten)¶
Here is the algorithm for the thread (FileManager::FileUpdater) which will periodically update the file cache and persist it.
D : The set of shared directories
T : Time during the hashes are computed (for example 30s)
F : A set of file initialy empty
- Add a watcher to the shared directories
// First synchronize (at start)
For each d in D (recursively) :
- Synchronize physical folders and files with d content
- Add in F the files which doesn't have computed hashes
Loop :
t : Time.now
For each f in F :
- Compute the unknown hash of files f
- Remove f from F
If (Time.now - t) > T : break
- Wait T - (Time.now - t)
- Wait for changes for a period of P
- When a modification occurs synchronise the file/folder
- Add each new file in F
- Persist the entire cache in a file (only every ~30min)
Downloading¶
See here : Protocol_core-core
Updated by Greg Burri over 16 years ago · 35 revisions